Inhalt
Poster
The German in Austria (DiÖ, ‚Deutsch in Österreich‘) annotations follow a standardised syntax. The tags a storaged in a database in a linear way. But the representation of the annotations is modelled hierarchically. An advantage is, that this representation guides the annotator through the annotation process.
annotation syntax
Tags are ordered in different generations. The zeroth generation of every annotation tier represents the phenomenon, which is assessed. In the example of the poster, the phenomenon dative passive (DATP) is examined.
A first generation represents the categories of a variable. Such as voice (GeVe) or recipient (Rez) for our dative passive example.
Every first generation has at least one second generation, which represents the category‘s features of a concrete variant. The category voice can have the features active (Akt) or passive (Pass), the category recipient can occur in different constituents, like object (Robj), subject (Rsubj), possessive pronoun (Rpposs) or not at all (R0).
Additionally, a second generation can have a third generation which give specifications of a feature. In the case of passive, this passive is further specified. Possibilities are werden passive (werdenP), bekommen passive (bekommenP), kriegen passive (kriegenP), lassen passive (lassenP) or a copula structure (KopulaK).
Tag set development process
The development of our tag sets follows a bottom-up approach. In a first step, one or a group of our linguists research for a particular linguistic phenomenon and create a first draft or concept of a tag set, following our annotation syntax. To test if the tag set draft works and covers all their needs, they do some test annotations outside the database, just in an excel file or something similar.
After this first steps from the academics side, the linguist comes to the annotation coordinator with his/her tag set concept. In the next step, the annotation coordinator adapts the tag set to the project standards and, if possible, to external standards. Thereby, both are in close contact to bring the tag set to its best.
After a final check by the academic, the annotation coordinator implements the new tag set in the database and the linguists can annotate their data right within the database.
Mapping tag sets
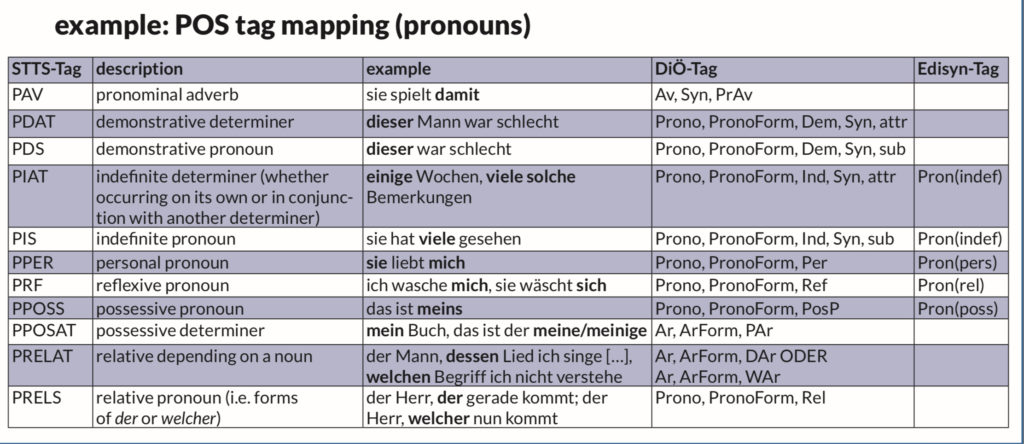
We try to model our tag sets comparing to existing standards. As our annotation syntax is specific, we map our tags to standard tags, if we are aware of them (if you know some good overview on annotation standards (except of POS), feel free to let me know 😉
As we annotate categories with their specifications, our annotations are normally over-specified compared to standards. An example you can see in the table below.
Additional information
For further information, just feel free to read our papers:
Breuer, L. M. / Seltmann, M. (2018): Sprachdaten(banken) – Aufbereitung und Visualisierung am Beispiel von SyHD und DiÖ (Publikation). In: Börner, I. / Straub, W. / Zolles, C. (Hg.): Germanistik digital. Digital Humanities in der Sprach- und Literaturwissenschaft, Facultas, 2018, 135-152. (DOI: https://phaidra.univie.ac.at/o:965244)
Lenz, A. N. / Breuer, L. M. / Fingerhuth, M. / Wittibschlager, A. / Seltmann, M. (In print): Exploring syntactic variation by means of “Language Production Experiments”- Methods from and analyses on German in Austria. To appear in Journal of Linguistic Geography.